Introducing pystringsext: Simplify Binary String Extraction in Python

When I needed to extract UUIDs from Android APKs, I found the stringsext command-line tool incredibly useful. However, it lacked programmable output for data analysis, which was crucial for my project. To bridge this gap, I created pystringsext, a Python wrapper that parses the standard output of the stringsext tool. This wrapper brings the power of binary string extraction to Python, making it a breeze to integrate into data analysis workflows. This tool simplifies the process of extracting and working with string data in your Python projects.
Key Features
- Multiple Encoding Support: Search for strings in various encodings, including UTF-8, UTF-16LE, and UTF-16BE, and more!
- Unicode Block Filtering: Easily filter strings based on specific Unicode blocks.
- ASCII Filtering: Apply ASCII filters to refine your search results.
- Multi-File Processing: Extract strings from multiple files in a single operation.
- Parsing Simplicity: Automatically parse the output into Python objects for easy manipulation.
Quick Start
Getting started with stringsext is straightforward:
- Install the library:
pip install stringsext - Import and use:
from pathlib import Path
from stringsext.core import Stringsext
from stringsext.encoding import EncodingName
extractor = Stringsext()
results = (
extractor.encoding(EncodingName.UTF_8, chars_min=4)
.add_file(Path("example.bin"))
.run()
)
findings = results.parse()
for finding in findings:
print(f"Found: {finding.content}, encoding: {finding.encoding_info.name}")
Note that without the .parse(), you can still use results.output to access the raw output from stringsext CLI.
UUID Extraction
Now, let's see how I built a UUID extractor based on my library:
import re
from pathlib import Path
from stringsext.core import Stringsext
from stringsext.encoding import EncodingName, UnicodeBlockFilter
def extract_uuids(content: str) -> set[str]:
"""Extract a set of UUIDs from a string."""
uuid_pattern = r"[a-fA-F0-9]{8}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{4}-[a-fA-F0-9]{12}"
return set(re.findall(uuid_pattern, content))
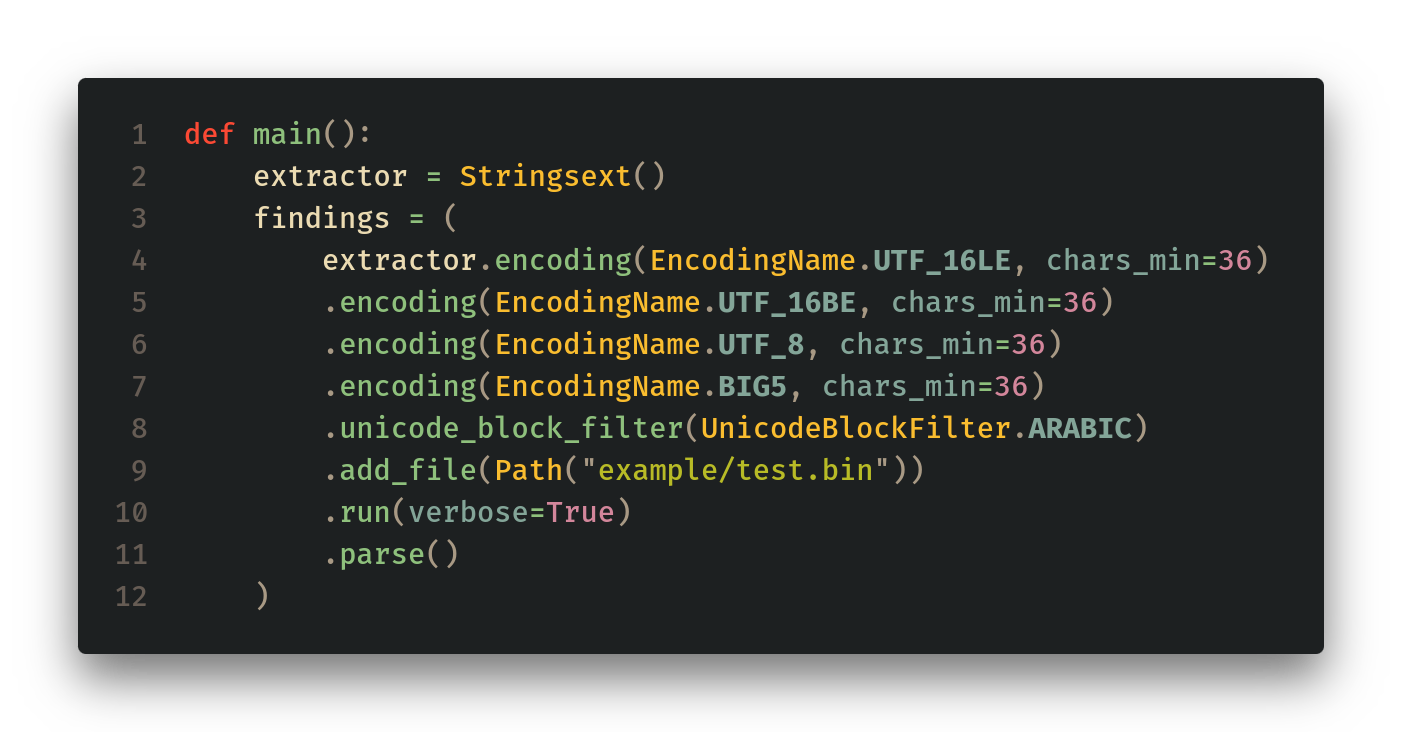
def main():
extractor = Stringsext()
findings = (
extractor.encoding(EncodingName.UTF_16LE, chars_min=36)
.encoding(EncodingName.UTF_16BE, chars_min=36)
.encoding(EncodingName.UTF_8, chars_min=36)
.encoding(EncodingName.BIG5, chars_min=36)
.unicode_block_filter(UnicodeBlockFilter.ARABIC)
.add_file(Path("example/test.bin"))
.run(verbose=True)
.parse()
)
for finding in findings:
uuids = extract_uuids(finding.content)
for uuid in uuids:
print(
f"Found UUID: {uuid}, encoding: {finding.encoding_info.name}, file: {finding.input_file}"
)
if __name__ == "__main__":
main()
Output:
❯ python hello.py
Running: /home/wyb/.cargo/bin/stringsext -e UTF-16LE,36,, -e UTF-16BE,36,, -e UTF-8,36,, -e Big5,36,, -u 0x3f000000 -t x -- example/test.bin
Found UUID: aec64acd-8c2a-4a11-9ece-ee6f2e969a77, encoding: UTF-8, file: example/test.bin
Found UUID: aec64acd-8c2a-4a11-9ece-ee6f2e969a77, encoding: Big5, file: example/test.bin
Found UUID: fb8fa624-a40f-4fd6-aeb8-d560bb3b9ac9, encoding: UTF-16LE, file: example/test.bin
Found UUID: 9abdc4ed-3935-40ad-81d9-043bbaed3b44, encoding: UTF-8, file: example/test.bin
Found UUID: 9abdc4ed-3935-40ad-81d9-043bbaed3b44, encoding: Big5, file: example/test.bin
Found UUID: 79a2c121-61d8-407e-a502-797f5dec2734, encoding: UTF-16BE, file: example/test.binWhy Use pystringsext?
- Simplicity: Say goodbye to complex command-line arguments and hello to a clean, intuitive Python API.
- Flexibility: Easily customize your string extraction with various encodings and filters.
- Integration: Seamlessly incorporate binary string extraction into your Python projects.
- Performance: Benefit from the speed of the underlying
stringsexttool with the convenience of Python.
Get Involved
stringsext is open-source and welcomes contributions! Check out our GitHub repository to learn more, report issues, or contribute to the project.